第一步我们先来爬取糗事百科的网页源码
糗事百科的网址是:http://www.qiushibaike.com/ 这也是我们等下要传入的url其实前面的最简单的爬虫程序就是爬取网页的源代码,现在我们试着用它来爬取糗事百科的源码,看看能不能成功#!/usr/bin/env python# -*- coding:UTF-8 -*-__author__ = '217小月月坑'import urllib2url = 'http://www.qiushibaike.com/'request = urllib2.Request(url)response = urllib2.urlopen(request)print response.read()
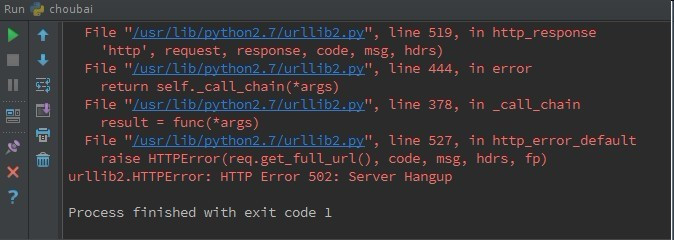
额......结果出错了,妈蛋,真是出师不利,那好吧,既然如此那我们就先来来认识错误
程序运行出错是很正常的,出的错误越多,我们就越能够在实践中积累知识,所以不要害怕错误。有的错误很明显,一检查程序就知道了,有的错误很隐蔽,可能要改几天结果发现却是多了一个空格或者是少了一个符号,所以我们要掌握一些方法来检查错误不仅仅是python,其他的编程语言在程序出错时会将错误信息输出,这个信息包括错误的类型,错误的代码在第几行,甚至是哪个变量出错了,所以我们要学会通过查找出错信息来分析错误原因并且解决错误,当然,为了方便,我们还需要一个能够显示行号的编辑器现在我们来看看上面这段程序报了什么错误